When you choose message passing or shared memory, you restrict the
kinds of information which you can express about your communications, even
though other information (perhaps expressible in other programming models)
might be useful to make the program more efficient in some cases, perhaps
on some architectures.
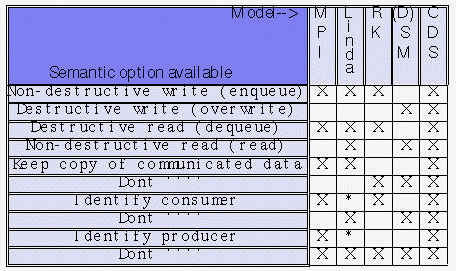
The preceding table demonstrates how restrictive these can be. The columns represent different programming models: Message passing, LindaTM, Reactive Kernel, shared memory (and distributed shared memory), and CDS. The rows represent the information that each model lets you express, described in more detail below. As you can see, unlike any of the other models, CDS allows the programmer to explicitly express any and all of these possibilities.
Description of table rows: (1) That you wish newly communicated data to be collected with old, (2) that you want newly communicated data to overwrite old, (3) that you want communicated data to vanish when received/read, (4) that you want the data to persist when received/read, (5) that the process initiating the communication will have further use for the data after the communication, (6) that the process will have no further need to access the data after the communication, (7) that the process knows which process will access the data next, (8) that the process doesn't know which process will access the data next, (9) that the process accessing communicated data knows which process created the data, and (10) that the accessing process doesn't know which process created the data. The asterisks in the Linda column represent that these possibilities can sometimes be filled in by a preprocessor which globally analyzes the program and recognizes matches between sender and consumer. Linda is a registered trademark of Scientific Computing Associates, Inc.
Copyright 2000 © elepar All rights reserved